MaxScale HA with Keepalived (CentOS/RedHat 7++)
This document aims to guide you through the implementation of what we call here as being the MaxScale HA with Keepalived. To introduce the subject and keep it as simple as possible, the keepalived is routing software written in C. Its main goal is to provide simple and robust facilities for load-balancing and provide high availability to environments, having the kernel module operating on layer4 (transport, TCP). Also, to be a faster layer than layer7, keepalived implementing its protocol which is the VRRP, will move the VIP between the configured interfaces so systems can continue accessing the same IP while using another underlying resource.
“VRRP specifies an election protocol that dynamically assigns responsibility for a virtual router to one of the VRRP routers on a LAN. The VRRP router controlling the IP address(es) associated with a virtual router is called the Master and forwards packets sent to these IP addresses. The election process provides dynamic failover in the forwarding responsibility should the Master become unavailable. It allows any of the virtual router IP addresses on the LAN to be used as the default first hop router by end-hosts. The advantage gained from using VRRP is a higher availability default path without requiring configuration of dynamic routing or router discovery protocols on every end-host.” [rfc2338]
Before going further:
The solution’s big picture:
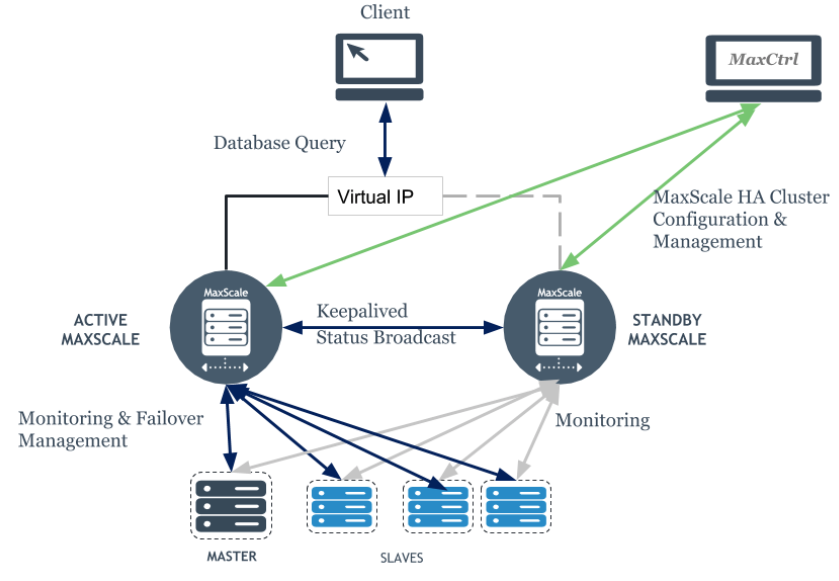
This document assumes you already have a set of MaxScale servers running, and you are going over the keepalived implementation (another document should be linked here to cover the MaxScale setup). Below you will see the backend IPs and the VIP to be configured on keepalived is 10.0.0.100, as you see later. The MaxScale server’s IPs are both 10.0.0.11 (box01) and 10.0.0.12 (box02).
#: My current environment has the below Replication Cluster [root@box01 ~]# maxctrl list servers ┌────────┬───────────┬──────┬─────────────┬─────────────────┬──────┐ │ Server │ Address │ Port │ Connections │ State │ GTID │ ├────────┼───────────┼──────┼─────────────┼─────────────────┼──────┤ │ box03 │ 10.0.0.13 │ 3306 │ 0 │ Master, Running │ │ └────────┴───────────┴──────┴─────────────┴─────────────────┴──────┘ │ box04 │ 10.0.0.14 │ 3306 │ 0 │ Slave, Running │ │ └────────┴───────────┴──────┴─────────────┴─────────────────┴──────┘ │ box05 │ 10.0.0.15 │ 3306 │ 0 │ Slave, Running │ │ └────────┴───────────┴──────┴─────────────┴─────────────────┴──────┘
Also, we consider the MaxScale version is 2.3++, and you already have dedicated configurations for the REST API port listening on a dedicated IP or over all the IPs. Below you can see what is recommended for the MaxScale global configurations on all the MaxScale instances you are going to work with.
[maxscale] threads = auto log_augmentation = 1 ms_timestamp = 1 syslog = 1 admin_host = 0.0.0.0 #: REST API on all interfaces - add a more restrictive valur if possible admin_port = 8989 #: The REST API port - add a more restrictive value if possible |
Special attention to SELinux, permissive or disabled is the best status for that. If a customer is using that, they will be able to provide a new target configuration for MaxScale and keepalived. This can be a big problem as keepalived will be using ephemeral ports and executing lots of scripts.
The steps this document goes through are below:
- Recognize the environment, knowing what hosts are currently dedicated to MaxScale;
- Packages installation, keepalived, and kernel-headers;
- Add configuration files for keepalived and the maxping.sh;
- Add the required user to execute scripts on behalf of keepalived;
- Configure Keepalived and MaxScale to start on boot;
- Monitor the syslog to observe the transitions.
Recognize the environment
It’s important to recognize the environment, and list the IPs; you can use the hosts’ file to set up a local DNS in case you don’t have very complicated hostnames, set up the SSH key-based authentication between MaxScale hosts, and make sure you have rsync and maxctrl available to work with. Maxctrl is already part of the package as one of the requirements here is to be running MaxScale 2.3++. The rsync package should be set up in case it’s not, and the rsync port (873) should also be observed from the firewall standpoint. With this, we can move on.
Packages installation on all MaxScale instances
One of the things to observe here is that most of the customer does not have access to the internet configured on the servers and then, a wget is suggested to test it:
[root@box01 ~]# wget --spider http://www.google.com Spider mode enabled. Check if remote file exists. --2019-03-06 20:41:42-- http://www.google.com/ Resolving www.google.com (www.google.com)... 172.217.162.164, 2800:3f0:4004:800::2004 Connecting to www.google.com (www.google.com)|172.217.162.164|:80... connected. HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Remote file exists and could contain further links, but recursion is disabled -- not retrieving. |
As you can see, the 200 is the HTTP response, so, we have access to the internet and we can set up the below packages:
$ yum install curl gcc openssl-devel libnl3-devel net-snmp-devel kernel-headers kernel-devel mailx keepalived -y
Add configuration files for keepalived and the maxping.sh
You can see below the configuration files for the MASTER and for the BACKUP sides, considering we have 2 MaxScale instances (if three, one MASTER and two BACKUP) and the maxping.sh which is a little script that demands a little customization so we can ask keepalived user to execute that script to check if it can list servers through maxctrl and recognize servers names by their names, so, the script executes with no errors passing the exit 0 messages to keepalived back which keep the current server as MASTER. Keeping the current server as master means that keepalived will keep the VIP on MASTER on the configured interface.
You need to pay attention here to the fact that, one server will operate as MASTER and the other one as BACKUP. Don’t add both as MASTER and with the same priority, that’s why I’m considering two configuration files below.
#: /etc/keepalived/keepalived.conf (for the MASTER MaxScale) global_defs { notification_email { customer@domain.com } notification_email_from box01@maxscaleservers smtp_server smtp.domain.com:25 smtp_connect_timeout 30 } vrrp_script chk_myscript { script "/usr/local/mariadb_rdba/maxping.sh" interval 2 fall 2 rise 2 } vrrp_instance VI_1 { state MASTER interface eth1 virtual_router_id 51 priority 101 advert_int 1 smtp_alert enable_script_security authentication { auth_type PASS auth_pass C97;*V69 } virtual_ipaddress { 10.0.0.100/24 } track_script { chk_myscript } notify /usr/local/mariadb_rdba/maxify.sh } |
Attention to the below BACKUP host configuration:
#: /etc/keepalived/keepalived.conf (for the BACKUP MaxScale) global_defs { notification_email { customer@domain.com } notification_email_from box01@maxscaleservers smtp_server smtp.domain.com:25 smtp_connect_timeout 30 } vrrp_script chk_myscript { script "/usr/local/mariadb_rdba/maxping.sh" interval 2 fall 2 rise 2 } vrrp_instance VI_1 { state BACKUP interface eth1 virtual_router_id 51 priority 100 advert_int 1 smtp_alert enable_script_security authentication { auth_type PASS auth_pass C97;*V69 } virtual_ipaddress { 10.0.0.100/24 } track_script { chk_myscript } notify /usr/local/mariadb_rdba/maxify.sh |
} |
Below is a small script executed by the keepalived (which has a user for that) which will be querying the server’s list out of MaxScale using the MaxCtrl client program, through the REST API configured to respond on port 8989, and will return the exit 0. This way, the MASTER role is kept. Otherwise, a new transition starts. Attention to the below script’s comments.
#!/bin/bash #: /usr/local/mariadb_rdba/maxping.sh - don't execute this below script with root user or, #: execute and remove the /tmp/maxping.txt before starting the keepalived.service officially #: avoid the syslog entry "exited with status 3" fileName="/tmp/maxping.txt" rm $fileName timeout 2s maxctrl list servers > $fileName to_result=$? if [ "$to_result" -ge 1 ]; then echo Timed out or error, timeout returned $to_result exit 3 else echo MaxCtrl success, rval is $to_result echo Checking maxadmin output sanity #: here you need to change/add to your servers names #: so that can be filtered out of the grep command grep1=$(grep box03 $fileName) #: my current master grep2=$(grep box04 $fileName) #: my slave01 grep3=$(grep box05 $fileName) #: my slave02 if [ "$grep1" ] && [ "$grep2" ] && [ "$grep3" ]; then echo All is fine exit 0 else echo Something is wrong exit 3 fi fi |
Adjust permissions:
chmod u+x /usr/local/mariadb_rdba/maxping.sh chown keepalived_script:root /usr/local/mariadb_rdba/maxping.sh |
The above script can for sure be improved, but, it fine does what it promises.
Add the required user to execute scripts on behalf of keepalived on all MaxScale instances
$ useradd -U -M -s /sbin/nologin keepalived_script |
Configure Keepalived and MaxScale to start on boot
$ systemctl enable keepalived.service $ systemctl start keepalived.service $ systemctl status keepalived.service | grep active $ systemctl enable maxscale.service $ systemctl start maxscale.service $ systemctl status maxscale.service | grep active |
After starting up the keepalived service, you can assess the VIP on the MASTER side, knowing that the MASTER will be the host with the keepalived configurations with the lowest priority. Below you can notice that I’m using the value configured at the interface parameter, th1 to filter results so we can see better the VIP added to that interface on MASTER:
[root@box01 ~]# ip addr | grep eth1 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 inet 10.0.0.11/24 brd 10.0.0.255 scope global noprefixroute eth1 inet 10.0.0.100/32 scope global eth1 |
Now you can ping the VIP:
[root@box01 ~]# ping -c 10 10.0.0.100 PING 10.0.0.100 (10.0.0.100) 56(84) bytes of data. 64 bytes from 10.0.0.100: icmp_seq=1 ttl=64 time=0.028 ms 64 bytes from 10.0.0.100: icmp_seq=2 ttl=64 time=0.026 ms 64 bytes from 10.0.0.100: icmp_seq=3 ttl=64 time=0.037 ms 64 bytes from 10.0.0.100: icmp_seq=4 ttl=64 time=0.038 ms 64 bytes from 10.0.0.100: icmp_seq=5 ttl=64 time=0.029 ms 64 bytes from 10.0.0.100: icmp_seq=6 ttl=64 time=0.030 ms 64 bytes from 10.0.0.100: icmp_seq=7 ttl=64 time=0.030 ms 64 bytes from 10.0.0.100: icmp_seq=8 ttl=64 time=0.036 ms 64 bytes from 10.0.0.100: icmp_seq=9 ttl=64 time=0.031 ms 64 bytes from 10.0.0.100: icmp_seq=10 ttl=64 time=0.028 ms --- 10.0.0.100 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 9025ms rtt min/avg/max/mdev = 0.026/0.031/0.038/0.005 ms |
And also test the access to the backends through MaxScale:
[root@box01 ~]# mysqladmin -umaxmon -p321 -h10.0.0.100 ping mysqld is alive |
PS: maxmon is a user I always use on my setups for the MaxScale GaleraMon/MariaDBMon.
Monitor the syslog to observe the transitions
Syslog is your friend in this scenario after and tailing it you can see the transitions, when the IP is attached/detached to/from interfaces:
#: starting the MASTER keepalived Mar 6 21:09:47 box01 systemd: Starting LVS and VRRP High Availability Monitor... Mar 6 21:09:47 box01 Keepalived[29208]: Starting Keepalived v1.3.5 (03/19,2017), git commit v1.3.5-6-g6fa32f2 Mar 6 21:09:47 box01 Keepalived[29208]: Opening file '/etc/keepalived/keepalived.conf'. Mar 6 21:09:47 box01 systemd: PID file /var/run/keepalived.pid not readable (yet?) after start. Mar 6 21:09:47 box01 Keepalived[29209]: Starting Healthcheck child process, pid=29210 Mar 6 21:09:47 box01 Keepalived[29209]: Starting VRRP child process, pid=29211 Mar 6 21:09:47 box01 systemd: Started LVS and VRRP High Availability Monitor. Mar 6 21:09:47 box01 Keepalived_healthcheckers[29210]: Opening file '/etc/keepalived/keepalived.conf'. Mar 6 21:09:47 box01 Keepalived_vrrp[29211]: Registering Kernel netlink reflector Mar 6 21:09:47 box01 Keepalived_vrrp[29211]: Registering Kernel netlink command channel Mar 6 21:09:47 box01 Keepalived_vrrp[29211]: Registering gratuitous ARP shared channel Mar 6 21:09:47 box01 Keepalived_vrrp[29211]: Opening file '/etc/keepalived/keepalived.conf'. Mar 6 21:09:47 box01 Keepalived_vrrp[29211]: Truncating auth_pass to 8 characters Mar 6 21:09:47 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) removing protocol VIPs. Mar 6 21:09:47 box01 Keepalived_vrrp[29211]: Using LinkWatch kernel netlink reflector... Mar 6 21:09:47 box01 Keepalived_vrrp[29211]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Mar 6 21:09:47 box01 Keepalived_vrrp[29211]: VRRP_Script(chk_myscript) succeeded Mar 6 21:09:48 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) Transition to MASTER STATE Mar 6 21:09:49 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) Entering MASTER STATE Mar 6 21:09:49 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) setting protocol VIPs. Mar 6 21:09:49 box01 Keepalived_vrrp[29211]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 6 21:09:49 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth1 for 10.0.0.100 Mar 6 21:09:49 box01 Keepalived_vrrp[29211]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 6 21:09:49 box01 Keepalived_vrrp[29211]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 6 21:09:49 box01 Keepalived_vrrp[29211]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 6 21:09:49 box01 Keepalived_vrrp[29211]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 6 21:09:49 box01 Keepalived_vrrp[29211]: Remote SMTP server [177.185.201.253]:25 connected. #: starting the BACKUP keepalived Mar 6 21:10:35 box02 systemd: Starting LVS and VRRP High Availability Monitor... Mar 6 21:10:35 box02 Keepalived[27512]: Starting Keepalived v1.3.5 (03/19,2017), git commit v1.3.5-6-g6fa32f2 Mar 6 21:10:35 box02 Keepalived[27512]: Opening file '/etc/keepalived/keepalived.conf'. Mar 6 21:10:35 box02 systemd: PID file /var/run/keepalived.pid not readable (yet?) after start. Mar 6 21:10:35 box02 Keepalived[27513]: Starting Healthcheck child process, pid=27514 Mar 6 21:10:35 box02 Keepalived[27513]: Starting VRRP child process, pid=27515 Mar 6 21:10:35 box02 systemd: Started LVS and VRRP High Availability Monitor. Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: Registering Kernel netlink reflector Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: Registering Kernel netlink command channel Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: Registering gratuitous ARP shared channel Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: Opening file '/etc/keepalived/keepalived.conf'. Mar 6 21:10:35 box02 Keepalived_healthcheckers[27514]: Opening file '/etc/keepalived/keepalived.conf'. Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: Truncating auth_pass to 8 characters Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: VRRP_Instance(VI_1) removing protocol VIPs. Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: Using LinkWatch kernel netlink reflector... Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: VRRP_Instance(VI_1) Entering BACKUP STATE Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Mar 6 21:10:35 box02 Keepalived_vrrp[27515]: Remote SMTP server [177.185.201.253]:25 connected. Mar 6 21:10:36 box02 Keepalived_vrrp[27515]: VRRP_Instance(VI_1) Now in FAULT state Mar 6 21:10:36 box02 Keepalived_vrrp[27515]: VRRP_Script(chk_myscript) succeeded Mar 6 21:10:37 box02 Keepalived_vrrp[27515]: VRRP_Instance(VI_1) Entering BACKUP STATE Mar 6 21:10:37 box02 Keepalived_vrrp[27515]: Remote SMTP server [177.185.201.253]:25 connected. |
If you need to force the failover to test transitions manually, edit the keepalived.conf and consider that, the host configured with the lowest priority will be the MASTER. One more hint is that this is all running in 5 Vagrant VMs so when you have private IPs and a virtualbox__intnet, it’s going form an internal network, and you have a range of IPs available to you. As we did here, pick up one to be the VIP and move forward.
About Transitions:
One thing to note accessing the syslog (/var/log/messages in our case) is that you can see the negotiation about who is the MASTER and who is the BACKUP. Starting up the keepalived on both boxes, you can see this below sequence:
Mar 29 17:48:29 box01 Keepalived[8569]: Starting Healthcheck child process, pid=8570 Mar 29 17:48:29 box01 Keepalived[8569]: Starting VRRP child process, pid=8571 Mar 29 17:48:29 box01 systemd: Started LVS and VRRP High Availability Monitor. Mar 29 17:48:29 box01 Keepalived_healthcheckers[8570]: Opening file '/etc/keepalived/keepalived.conf'. Mar 29 17:48:29 box01 Keepalived_vrrp[8571]: Registering Kernel netlink reflector Mar 29 17:48:29 box01 Keepalived_vrrp[8571]: Registering Kernel netlink command channel Mar 29 17:48:29 box01 Keepalived_vrrp[8571]: Registering gratuitous ARP shared channel Mar 29 17:48:29 box01 Keepalived_vrrp[8571]: Opening file '/etc/keepalived/keepalived.conf'. Mar 29 17:48:29 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) removing protocol VIPs. Mar 29 17:48:29 box01 Keepalived_vrrp[8571]: Using LinkWatch kernel netlink reflector... Mar 29 17:48:29 box01 Keepalived_vrrp[8571]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Mar 29 17:48:29 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) Transition to MASTER STATE Mar 29 17:48:30 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) Entering FAULT STATE Mar 29 17:48:30 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) Now in FAULT state Mar 29 17:48:35 box01 Keepalived_vrrp[8571]: VRRP_Script(chk_myscript) succeeded Mar 29 17:48:36 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) Entering BACKUP STATE Mar 29 17:48:37 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) forcing a new MASTER election Mar 29 17:48:38 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) Transition to MASTER STATE Mar 29 17:48:39 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) Entering MASTER STATE Mar 29 17:48:39 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) setting protocol VIPs. Mar 29 17:48:39 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 29 17:48:39 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth1 for 10.0.0.100 Mar 29 17:48:39 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 29 17:48:39 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 29 17:48:39 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 29 17:48:39 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 29 17:48:44 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 29 17:48:44 box01 Keepalived_vrrp[8571]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth1 for 10.0.0.100 Mar 29 17:48:44 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 29 17:48:44 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 29 17:48:44 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 Mar 29 17:48:44 box01 Keepalived_vrrp[8571]: Sending gratuitous ARP on eth1 for 10.0.0.100 |
From the above, you can clearly see who is the current MASTER. But, how is it on the BACKUP side?
Mar 29 17:52:49 box02 Keepalived[5524]: Starting Healthcheck child process, pid=5525 Mar 29 17:52:49 box02 Keepalived[5524]: Starting VRRP child process, pid=5526 Mar 29 17:52:49 box02 systemd: Started LVS and VRRP High Availability Monitor. Mar 29 17:52:49 box02 Keepalived_healthcheckers[5525]: Opening file '/etc/keepalived/keepalived.conf'. Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: Registering Kernel netlink reflector Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: Registering Kernel netlink command channel Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: Registering gratuitous ARP shared channel Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: Opening file '/etc/keepalived/keepalived.conf'. Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: VRRP_Instance(VI_1) removing protocol VIPs. Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: Using LinkWatch kernel netlink reflector... Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: VRRP_Script(chk_myscript) succeeded Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: VRRP_Instance(VI_1) Transition to MASTER STATE Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: VRRP_Instance(VI_1) Received advert with higher priority 101, ours 100 Mar 29 17:52:49 box02 Keepalived_vrrp[5526]: VRRP_Instance(VI_1) Entering BACKUP STATE |
You see the priority comparison between the two hosts and win the one having the highest vrrp_scrip.priority.
In the end, what you see is the VIP added to the vrrp_scrip.interface on the MASTER:
[root@box01 ~]# ip addr show eth1 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 08:00:27:09:15:27 brd ff:ff:ff:ff:ff:ff inet 10.0.0.11/24 brd 10.0.0.255 scope global noprefixroute eth1 valid_lft forever preferred_lft forever inet 10.0.0.100/24 scope global secondary eth1 valid_lft forever preferred_lft forever inet6 fe80::a00:27ff:fe09:1527/64 scope li |
MaxScale Passive Mode
When running the MaxScale HA with keepalived and dealing with Replication Clusters, we need to protect the environment against operational mistakes that could happen as both sides the MASTER and the BACKUP MaxScales will have MaxScale instances up and running and accepting connections, despite of just one side being active at-a-time as the VIP in one side only (unless you resolve to do bad things and point the so-called small apps to the passive MaxScale endpoint directly – this is bad!!). To protect the environment, MaxScale can be set in Passive mode and in that mode, the switchover/failover/automatic rejoin won’t be triggered. These operations will be triggered only on the active MaxScale.
#!/bin/bash TYPE=$1 NAME=$2 STATE=$3 OUTFILE=/tmp/maxify.log case $STATE in "MASTER") echo "Setting this MaxScale node to active mode" > $OUTFILE maxctrl alter maxscale passive false exit 0 ;; "BACKUP") echo "Setting this MaxScale node to passive mode" > $OUTFILE maxctrl alter maxscale passive true exit 0 ;; "FAULT") echo "MaxScale failed the status check." > $OUTFILE maxctrl alter maxscale passive true exit 0 ;; *) echo "Unknown state" > $OUTFILE exit 1 ;; esac |
Adjust then the script permissions and ownership:
#: the maxify need to be like the below chmod u+x /usr/local/mariadb_rdba/maxify.sh chown keepalived_script:root /usr/local/mariadb_rdba/maxify.sh |
Additional notes:
On some setups and implementations, I’ve seen the signal 15 being sent to the keepalived process what can make a transition to happen. Looking to see if other users have the same issue, I found this post on GitHub. The recommendation was to add a local DNS resolution and increase the vrrp_scrip.interval from the current value to something else bigger so the problem can be solved. The events appearing on syslog is like the ones below:
Mar 7 20:36:06 box01 Keepalived_vrrp[29211]: VRRP_Script(chk_myscript) timed out Mar 7 20:36:06 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) Entering FAULT STATE Mar 7 20:36:06 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) removing protocol VIPs. Mar 7 20:36:06 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) Now in FAULT state Mar 7 20:36:06 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:08 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:12 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:14 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:16 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:18 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:20 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:22 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:24 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:28 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:30 box01 Keepalived_vrrp[29211]: /usr/local/mariadb_rdba/maxping.sh exited due to signal 15 Mar 7 20:36:33 box01 Keepalived_vrrp[29211]: VRRP_Script(chk_myscript) succeeded Mar 7 20:36:35 box01 Keepalived_vrrp[29211]: Kernel is reporting: interface eth1 UP Mar 7 20:36:35 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1): Transition to MASTER STATE Mar 7 20:36:35 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) Transition to MASTER STATE Mar 7 20:36:36 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) Entering MASTER STATE Mar 7 20:36:36 box01 Keepalived_vrrp[29211]: VRRP_Instance(VI_1) setting protocol VIPs. Mar 7 20:36:36 box01 Keepalived_vrrp[29211]: Sending gratuitous ARP on eth1 for 10.0.0.100 |
When debugging the above signal 15, it can interchange for signal 3 also, and considering my experience, it can be a mixture of very low timeout command within the maxping.sh and the vrrp_scrip.interval. For small boxes or even, networks with high latency, I recommend you to have greater values. It can start flapping and the IP will be moving around many times. Here you need to search a good balance. It’s good to mention that high values for the vrrp_scrip.interval will give you more time for the VRRP to realize it’s in the FAULT state and that the transition should be triggered.
Another issue you can face is when SELinux is being enforced and the below messages will appear on syslog:
Apr 4 20:49:27 uat-maxsq01 Keepalived_vrrp[7517]: Couldn't setuid: 1000 (Operation not permitted) Apr 4 20:49:29 uat-maxsq01 Keepalived_vrrp[7519]: Couldn't setuid: 1000 (Operation not permitted) Apr 4 20:49:31 uat-maxsq01 Keepalived_vrrp[7522]: Couldn't setuid: 1000 (Operation not permitted) Apr 4 20:49:33 uat-maxsq01 Keepalived_vrrp[7528]: Couldn't setuid: 1000 (Operation not permitted) Apr 4 20:49:35 uat-maxsq01 Keepalived_vrrp[7577]: Couldn't setuid: 1000 (Operation not permitted) Apr 4 20:49:37 uat-maxsq01 Keepalived_vrrp[7580]: Couldn't setuid: 1000 (Operation not permitted)
You just need to setenforce 0 to make it able to do what it needs to do.
[root@uat-maxsq01 ~]# setenforce 0 [root@uat-maxsq01 ~]#
And then you can see the action being completed yet tailing the syslog:
Apr 4 20:50:01 uat-maxsq01 systemd: Created slice User Slice of root. Apr 4 20:50:01 uat-maxsq01 systemd: Started Session 1415 of user root. Apr 4 20:50:01 uat-maxsq01 systemd: Removed slice User Slice of root.
It’s clear that something else happened that made the maxping.sh script execution to fail, starting a transition on the current MASTER.
You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.
Leave a Reply