MariaDB 10.1, MSR and MTS
As a preparation of my presentation together with Max Bubenick at 2016’s Percona Live, happening in Santa Clara, CA, US, I’m running as many tests as I can to check all the maturity of the technology of feature we are about to talking about. This is a common sense that you need to go over the planned to be presented feature in order to address some of the implicit subjects. This way, we stared discussing about a crash on MariaDB 10.1 setup for a Multi-Source Replication Slave, being this slave server a Multi-Threaded Slave as well running with 12 threads dedicated to execute raw updates from the relay log, having at least 3 out of those 12 threads dedicated to each of the exiting domain_id. You can check the numbers of threads dedicated to each domain_id interpreting the contents of mysql.gtid_slave_pos table to keep track of their current position (the global transaction ID of the last transaction applied). Using the table allows the slave to maintain a consistent value for the gtid_slave_pos system variable across server restarts. That is, as a I have setup 3 masters and one multi-source slave, in this scenario I’ve got domains #2, #3, #4, being the multi-source slave the domain #1. That justifies the 12 threads and at least 3 for each domain.
Below, the designed architecture:
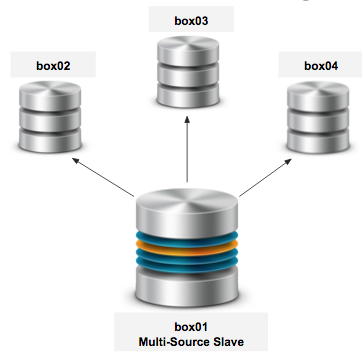
box01 - @@server_id=1, @@gtid_domain_id=1 box02 - @@server_id=2, @@gtid_domain_id=2 box03 - @@server_id=3, @@gtid_domain_id=3 box04 - @@server_id=4, @@gtid_domain_id=4 |
After configuring the multi-source replication and having configuration files well set, I started some tests.
#: Connection name with box02 MariaDB [(none)]> change master 'box02' to master_host='192.168.0.102', master_user='repl', master_password='Bi@nchI', master_use_gtid=current_pos; #: Connection name with box03 MariaDB [(none)]> change master 'box03' to master_host='192.168.0.102', master_user='repl', master_password='Bi@nchI', master_use_gtid=current_pos; #: Connection name with box04 MariaDB [(none)]> change master 'box04' to master_host='192.168.0.104', master_user='repl', master_password='Bi@nchI', master_use_gtid=current_pos; |
Just to make sure we’re on the same page, I created on the master’s side individual databases to make the masters to write just to their own database schema to avoid conflicts on writing to the same table (that’s an existing successful case I have to formulate a new blog to tell). So, after that, I used sysbench to prepare the test case, creating 10 tables in each database schema with 10000 rows each table. Finally, I run sysbench with the following structure to execute a simple 60 secs test using OLTP script:
[vagrant@maria0X ~]$ sudo sysbench --test=/usr/share/doc/sysbench/tests/db/oltp.lua --oltp-table-size=10000 --mysql-db=box0X --oltp-tables-count=10 --mysql-user=root --db-driver=mysql --mysql-table-engine=innodb --max-time=60 --max-requests=0 --report-interval=60 --num-threads=50 --mysql-engine-trx=yes run |
I started the above sysbench on all the three masters and then, the multi-source slave has crashed with the below error:
2016-03-23 19:54:57 140604957547264 [ERROR] Slave (additional info): Commit failed due to failure of an earlier commit on which this one depends Error_code: 1964 2016-03-23 19:54:57 140604957547264 [Warning] Slave: Running in read-only mode Error_code: 1836 2016-03-23 19:54:57 140604957547264 [Warning] Slave: Table 'sbtest2' is read only Error_code: 1036 2016-03-23 19:54:57 140604957547264 [Warning] Slave: Commit failed due to failure of an earlier commit on which this one depends Error_code: 1964 2016-03-23 19:54:57 140604957547264 [Warning] Slave: Commit failed due to failure of an earlier commit on which this one depends Error_code: 1964 2016-03-23 19:54:57 140604957547264 [Warning] Slave: Commit failed due to failure of an earlier commit on which this one depends Error_code: 1964 [...snip...] 2016-03-23 19:54:57 140604957244160 [ERROR] Slave (additional info): Commit failed due to failure of an earlier commit on which this one depends Error_code: 1964 2016-03-23 19:54:57 140604957244160 [Warning] Slave: Running in read-only mode Error_code: 1836 2016-03-23 19:54:57 140604957244160 [Warning] Slave: Table 'sbtest1' is read only Error_code: 1036 2016-03-23 19:54:57 140604957244160 [Warning] Slave: Commit failed due to failure of an earlier commit on which this one depends Error_code: 1964 2016-03-23 19:54:57 140604957244160 [Warning] Slave: Commit failed due to failure of an earlier commit on which this one depends Error_code: 1964 2016-03-23 19:54:57 140604957244160 [Warning] Slave: Commit failed due to failure of an earlier commit on which this one depends Error_code: 1964 [...snip...] 2016-03-23 19:59:14 140604959972096 [Note] /usr/sbin/mysqld: Normal shutdown |
The problem here is clear, “Commit failed due to failure of an earlier commit on which this one depends”.
Furthermore, when I tried to start multi-source slave back, I found the following events added to the error log:
2016-03-23 19:59:17 139987887904800 [Note] /usr/sbin/mysqld (mysqld 10.1.11-MariaDB-log) starting as process 3996 ... 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Using mutexes to ref count buffer pool pages 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: The InnoDB memory heap is disabled 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Memory barrier is not used 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Compressed tables use zlib 1.2.3 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Using Linux native AIO 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Using generic crc32 instructions 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Initializing buffer pool, size = 128.0M 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Completed initialization of buffer pool 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Highest supported file format is Barracuda. InnoDB: Transaction 46834 was in the XA prepared state. InnoDB: Transaction 46834 was in the XA prepared state. InnoDB: Transaction 46835 was in the XA prepared state. InnoDB: Transaction 46835 was in the XA prepared state. InnoDB: Transaction 46836 was in the XA prepared state. InnoDB: Transaction 46836 was in the XA prepared state. InnoDB: Transaction 46838 was in the XA prepared state. InnoDB: Transaction 46838 was in the XA prepared state. InnoDB: Transaction 46839 was in the XA prepared state. InnoDB: Transaction 46839 was in the XA prepared state. InnoDB: 6 transaction(s) which must be rolled back or cleaned up InnoDB: in total 4 row operations to undo InnoDB: Trx id counter is 47616 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: 128 rollback segment(s) are active. 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Waiting for purge to start InnoDB: Starting in background the rollback of uncommitted transactions 2016-03-23 19:59:17 7f51503fe700 InnoDB: Rolling back trx with id 46837, 4 rows to undo 2016-03-23 19:59:17 139987215443712 [Note] InnoDB: Rollback of trx with id 46837 completed 2016-03-23 19:59:17 7f51503fe700 InnoDB: Rollback of non-prepared transactions completed 2016-03-23 19:59:17 139987887904800 [Note] InnoDB: Percona XtraDB (http://www.percona.com) 5.6.26-76.0 started; log sequence number 124266988 2016-03-23 19:59:17 139987887904800 [Note] Plugin 'FEEDBACK' is disabled. 2016-03-23 19:59:17 7f517854d820 InnoDB: Starting recovery for XA transactions... 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction 46839 in prepared state after recovery 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction contains changes to 7 rows 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction 46838 in prepared state after recovery 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction contains changes to 5 rows 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction 46836 in prepared state after recovery 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction contains changes to 7 rows 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction 46835 in prepared state after recovery 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction contains changes to 5 rows 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction 46834 in prepared state after recovery 2016-03-23 19:59:17 7f517854d820 InnoDB: Transaction contains changes to 7 rows 2016-03-23 19:59:17 7f517854d820 InnoDB: 5 transactions in prepared state after recovery 2016-03-23 19:59:17 139987887904800 [Note] Found 5 prepared transaction(s) in InnoDB 2016-03-23 19:59:17 139987887904800 [ERROR] Found 5 prepared transactions! It means that mysqld was not shut down properly last time and critical recovery information (last binlog or tc.log file) was manually deleted after a crash. You have to start mysqld with --tc-heuristic-recover switch to commit or rollback pending transactions. 2016-03-23 19:59:17 139987887904800 [ERROR] Aborting |
So, to get the MSR Slave back:
[vagrant@maria01 ~]$ sudo mysqld --defaults-file=/etc/my.cnf --tc-heuristic-recover=ROLLBACK 2016-03-23 20:18:20 140348206848032 [Note] mysqld (mysqld 10.1.11-MariaDB-log) starting as process 4047 ... 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Using mutexes to ref count buffer pool pages 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: The InnoDB memory heap is disabled 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Memory barrier is not used 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Compressed tables use zlib 1.2.3 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Using Linux native AIO 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Using generic crc32 instructions 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Initializing buffer pool, size = 128.0M 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Completed initialization of buffer pool 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Highest supported file format is Barracuda. InnoDB: Transaction 46834 was in the XA prepared state. InnoDB: Transaction 46834 was in the XA prepared state. InnoDB: Transaction 46835 was in the XA prepared state. InnoDB: Transaction 46835 was in the XA prepared state. InnoDB: Transaction 46836 was in the XA prepared state. InnoDB: Transaction 46836 was in the XA prepared state. InnoDB: Transaction 46838 was in the XA prepared state. InnoDB: Transaction 46838 was in the XA prepared state. InnoDB: Transaction 46839 was in the XA prepared state. InnoDB: Transaction 46839 was in the XA prepared state. InnoDB: 5 transaction(s) which must be rolled back or cleaned up InnoDB: in total 0 row operations to undo InnoDB: Trx id counter is 48128 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: 128 rollback segment(s) are active. 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Waiting for purge to start InnoDB: Starting in background the rollback of uncommitted transactions 2016-03-23 20:18:21 7fa534bff700 InnoDB: Rollback of non-prepared transactions completed 2016-03-23 20:18:21 140348206848032 [Note] InnoDB: Percona XtraDB (http://www.percona.com) 5.6.26-76.0 started; log sequence number 124267433 2016-03-23 20:18:21 140348206848032 [Note] Plugin 'FEEDBACK' is disabled. 2016-03-23 20:18:21 140348206848032 [Note] Heuristic crash recovery mode 2016-03-23 20:18:21 7fa55d039820 InnoDB: Starting recovery for XA transactions... 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction 46839 in prepared state after recovery 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction contains changes to 7 rows 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction 46838 in prepared state after recovery 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction contains changes to 5 rows 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction 46836 in prepared state after recovery 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction contains changes to 7 rows 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction 46835 in prepared state after recovery 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction contains changes to 5 rows 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction 46834 in prepared state after recovery 2016-03-23 20:18:21 7fa55d039820 InnoDB: Transaction contains changes to 7 rows 2016-03-23 20:18:21 7fa55d039820 InnoDB: 5 transactions in prepared state after recovery 2016-03-23 20:18:21 140348206848032 [Note] Found 5 prepared transaction(s) in InnoDB 2016-03-23 20:18:21 140347457898240 [Note] InnoDB: Dumping buffer pool(s) not yet started 2016-03-23 20:18:21 140348206848032 [Note] Please restart mysqld without --tc-heuristic-recover 2016-03-23 20:18:21 140348206848032 [ERROR] Can't init tc log 2016-03-23 20:18:21 140348206848032 [ERROR] Aborting |
And finally:
[vagrant@maria01 ~]$ sudo service mysql start Starting MySQL... SUCCESS! |
By the way, as per the discussion on twitter, I’m not really sure yet if this is a problem related to the in-order commit when using parallel replication which implies that a transaction commit conflict is happening at that point. Below the configuration file used for the MSR Slave, showing that it’s configured with @@slave_pararllel_mode=optimistic which as per the manual online “tries to apply most transactional DML in parallel, and handles any conflicts with rollback and retry”, more info here.
#: box01 - multi-source slave [client] port=3306 socket=/var/lib/mysql/mysql.sock [mysqld] user=mysql port=3306 socket=/var/lib/mysql/mysql.sock basedir=/usr datadir=/var/lib/mysql read_only=1 #: repl vars server_id=1 report_host=box01 report_port=3306 report_user=repl log_bin=mysql-bin log_bin_index=mysql.index log_slave_updates=true binlog_format=ROW #: verify checksum on master master_verify_checksum=1 #: gtid vars gtid_domain_id=1 gtid_ignore_duplicates=ON gtid_strict_mode=1 #: msr slave parallel mode * box02.slave_parallel_mode=conservative box03.slave_parallel_mode=conservative box04.slave_parallel_mode=conservative slave_parallel_threads=10 slave_domain_parallel_threads=2 slave_parallel_max_queued=512M slave_net_timeout=15 slave_sql_verify_checksum=1 slave_compressed_protocol=1 #: binary log group commit behavior #binlog_commit_wait_usec=100000 #binlog_commit_wait_count=20 |
Maybe a test using @@slave_domain_parallel_threads should be done as the next step, but, if you have any additional thoughts on this, it’s really appreciated.
Continuing with this, I found that Connection Names were not running in optimistic mode (it was conservative, which limits parallelism in an effort to avoid any conflicts) and then after changing that, I did the test again:
#: current values MariaDB [(none)]> show all slaves status\G Connection_name: box02 Parallel_Mode: conservative Connection_name: box03 Parallel_Mode: conservative Connection_name: box04 Parallel_Mode: conservative 3 rows in set (0.00 sec) #: changing Parallel Mode to Optimistic MariaDB [(none)]> stop all slaves; Query OK, 0 rows affected, 3 warnings (0.00 sec) MariaDB [(none)]> set global box02.slave_parallel_mode='optimistic'; Query OK, 0 rows affected (0.00 sec) MariaDB [(none)]> set global box03.slave_parallel_mode='optimistic'; Query OK, 0 rows affected (0.00 sec) MariaDB [(none)]> set global box04.slave_parallel_mode='optimistic'; Query OK, 0 rows affected (0.00 sec) MariaDB [(none)]> start all slaves; Query OK, 0 rows affected, 3 warnings (0.02 sec) MariaDB [(none)]> show all slaves status\G Connection_name: box02 Parallel_Mode: optimistic Connection_name: box03 Parallel_Mode: optimistic Connection_name: box04 Parallel_Mode: optimistic 3 rows in set (0.00 sec) |
The parallel threads were like:
MariaDB [(none)]> SELECT ID,TIME,STATE,USER FROM INFORMATION_SCHEMA.PROCESSLIST WHERE USER='system user'; +----+------+------------------------------------------------------------------+-------------+ | ID | TIME | STATE | USER | +----+------+------------------------------------------------------------------+-------------+ | 46 | 81 | Slave has read all relay log; waiting for the slave I/O thread t | system user | | 45 | 81 | Waiting for master to send event | system user | | 44 | 86 | Slave has read all relay log; waiting for the slave I/O thread t | system user | | 43 | 86 | Waiting for master to send event | system user | | 42 | 102 | Slave has read all relay log; waiting for the slave I/O thread t | system user | | 41 | 102 | Waiting for master to send event | system user | | 35 | 0 | Waiting for prior transaction to commit | system user | | 34 | 0 | Waiting for prior transaction to commit | system user | | 33 | 0 | Waiting for prior transaction to commit | system user | | 32 | 175 | Waiting for work from SQL thread | system user | | 31 | 175 | Waiting for work from SQL thread | system user | | 30 | 0 | Unlocking tables | system user | | 29 | 0 | Unlocking tables | system user | | 28 | 0 | Unlocking tables | system user | | 27 | 175 | Waiting for work from SQL thread | system user | | 26 | 175 | Waiting for work from SQL thread | system user | +----+------+------------------------------------------------------------------+-------------+ 16 rows in set (0.00 sec) |
Additionally, I’m curious to check now the Retried_transactions per connection Name variable to check if the retry transactions part of the optimistic parallel replication mode is really working:
MariaDB [(none)]> pager egrep "Connection|Parallel|Gtid_IO|Retried" PAGER set to 'egrep "Connection|Parallel|Gtid_IO|Retried"' MariaDB [(none)]> show all slaves status\G Connection_name: box02 Gtid_IO_Pos: 1-1-68,4-4-87933,3-3-77410,2-2-149378 Parallel_Mode: optimistic Retried_transactions: 12 Connection_name: box03 Gtid_IO_Pos: 1-1-68,4-4-87933,3-3-88622,2-2-131340 Parallel_Mode: optimistic Retried_transactions: 3 Connection_name: box04 Gtid_IO_Pos: 1-1-68,4-4-98365,3-3-77410,2-2-131340 Parallel_Mode: optimistic Retried_transactions: 3 3 rows in set (0.02 sec) |
Additionally, we can check that the global status variable Slave_retried_transactions finnally reflects the total value to retried transactions by Connection Names on MSR Slave:
MariaDB [(none)]> show global status like 'Slave_retried%'; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | Slave_retried_transactions | 18 | +----------------------------+-------+ 1 row in set (0.00 sec) |
So, it’s solved, slave hasn’t crashed anymore, but the question why did the MSR Slave crashed is not solved yet. But, what was learnt here was that, we can use also minimal besides of conservative for slave_parallel_mode that will play very good in this case as it’s going to only parallelizes the commit steps of transactions, this is the next test I would like to realize as the next step on this ever growing post. I’m going to try another post to check the relation between transaction’s conflicts rate and performance impact over the exiting slave parallel mode.
You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.
Leave a Reply